Robust Phase Retrieval with Prior Knowledge
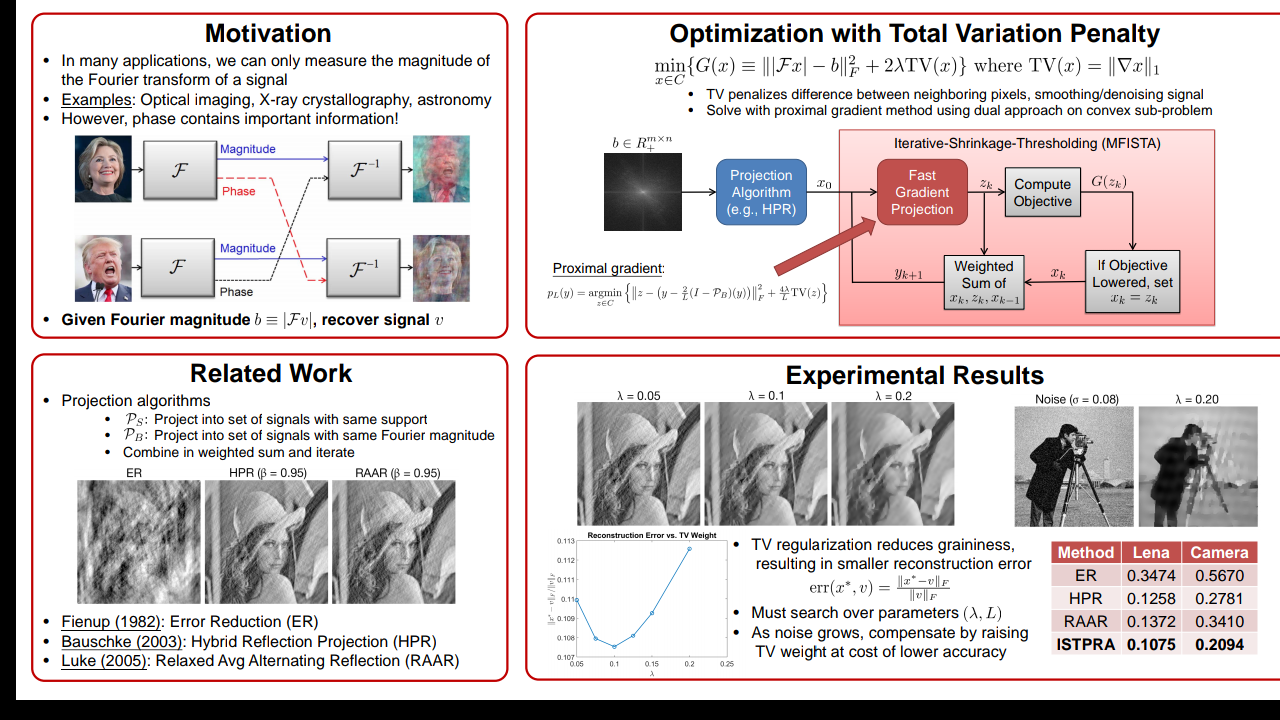
Robust Phase Retrieval with Prior Knowledge Output 1 Introduction In many imaging applications, one can only measure the power spectral den-sity (the magnitude of the Fourier transform) and not the phase of the signalof interest. For example, in optical settings, devices like CCD cameras only capture the photon flux, so important information stored in the phase is lost.The challenge is to reconstruct the original signal from measurements of its Fourier magnitude. This problem, known as phase retrieval, arises in many scientific and engineering applications, including optics, crystallography, and astronomy. 2 Problem Description Suppose x = (x1, . . . , xN ) is a non-negative signal, and denote by F : x → F the operator that returns its N-point discrete Fourier transform (DFT). We observe b = (b1, . . . , bN ) ∈ R N+ , the magnitude of the Fourier transform of the signal, and wish to find x that satisfies |Fx| = b. Phase retrieval can be posed ...